data = pd.merge(pd.merge(ratings,users),movies) data.ix[0]
.ix is deprecated. Please use .loc for label based indexing or .iloc for positional indexing data.iloc[0]
data.iloc[0] Out[58]: user_id 1 movie_id 1193 rating 5 timestamp 978300760 gender F age 1 occupation 10 zip 48067 title One Flew Over the Cuckoo's Nest (1975) genres Drama Name: 0, dtype: object
mean_ratings[:5] Out[74]: gender F M title $1,000,000 Duck (1971) 3.375000 2.761905 'Night Mother (1986) 3.388889 3.352941 'Til There Was You (1997) 2.675676 2.733333 'burbs, The (1989) 2.793478 2.962085 ...And Justice for All (1979) 3.828571 3.689024
Out[75]: title $1,000,000 Duck (1971) 37 'Night Mother (1986) 70 'Til There Was You (1997) 52 'burbs, The (1989) 303 ...And Justice for All (1979) 199 1-900 (1994) 2 10 Things I Hate About You (1999) 700 101 Dalmatians (1961) 565 101 Dalmatians (1996) 364 12 Angry Men (1957) 616 dtype: int64
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
active_titles = ratings_by_title.index[ratings_by_title >=250] active_titles Out[83]: Index([''burbs, The (1989)', '10 Things I Hate About You (1999)', '101 Dalmatians (1961)', '101 Dalmatians (1996)', '12 Angry Men (1957)', '13th Warrior, The (1999)', '2 Days in the Valley (1996)', '20,000 Leagues Under the Sea (1954)', '2001: A Space Odyssey (1968)', '2010 (1984)', ... 'X-Men (2000)', 'Year of Living Dangerously (1982)', 'Yellow Submarine (1968)', 'You've Got Mail (1998)', 'Young Frankenstein (1974)', 'Young Guns (1988)', 'Young Guns II (1990)', 'Young Sherlock Holmes (1985)', 'Zero Effect (1998)', 'eXistenZ (1999)'], dtype='object', name='title', length=1216)
该索引中含有评分数据大于250条的电影名称,然后从mean_ratings中选取所需的行:
1
mean_ratings = mean_ratings.loc[active_titles]
为了了解女性观众最喜欢的电影,我们可以对F列降序排列:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
top_female_ratings = mean_ratings.sort_values(by='F',ascending=False) top_female_ratings[:10] Out[98]: gender F M title Close Shave, A (1995) 4.644444 4.473795 Wrong Trousers, The (1993) 4.588235 4.478261 Sunset Blvd. (a.k.a. Sunset Boulevard) (1950) 4.572650 4.464589 Wallace & Gromit: The Best of Aardman Animation... 4.563107 4.385075 Schindler's List (1993) 4.562602 4.491415 Shawshank Redemption, The (1994) 4.539075 4.560625 Grand Day Out, A (1992) 4.537879 4.293255 To Kill a Mockingbird (1962) 4.536667 4.372611 Creature Comforts (1990) 4.513889 4.272277 Usual Suspects, The (1995) 4.513317 4.518248
sorted_by_diff = mean_ratings.sort_values(by='diff') sorted_by_diff[:15] Out[102]: gender F M diff title Dirty Dancing (1987) 3.790378 2.959596 -0.830782 Jumpin' Jack Flash (1986) 3.254717 2.578358 -0.676359 Grease (1978) 3.975265 3.367041 -0.608224 Little Women (1994) 3.870588 3.321739 -0.548849 Steel Magnolias (1989) 3.901734 3.365957 -0.535777 Anastasia (1997) 3.800000 3.281609 -0.518391 Rocky Horror Picture Show, The (1975) 3.673016 3.160131 -0.512885 Color Purple, The (1985) 4.158192 3.659341 -0.498851 Age of Innocence, The (1993) 3.827068 3.339506 -0.487561 Free Willy (1993) 2.921348 2.438776 -0.482573 French Kiss (1995) 3.535714 3.056962 -0.478752 Little Shop of Horrors, The (1960) 3.650000 3.179688 -0.470312 Guys and Dolls (1955) 4.051724 3.583333 -0.468391 Mary Poppins (1964) 4.197740 3.730594 -0.467147 Patch Adams (1998) 3.473282 3.008746 -0.464536
对排序结果反序并取出前15行,得到的则是男性观众更喜欢的电影:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
sorted_by_diff[::-1][:15] Out[104]: gender F M diff title Good, The Bad and The Ugly, The (1966) 3.494949 4.221300 0.726351 Kentucky Fried Movie, The (1977) 2.878788 3.555147 0.676359 Dumb & Dumber (1994) 2.697987 3.336595 0.638608 Longest Day, The (1962) 3.411765 4.031447 0.619682 Cable Guy, The (1996) 2.250000 2.863787 0.613787 Evil Dead II (Dead By Dawn) (1987) 3.297297 3.909283 0.611985 Hidden, The (1987) 3.137931 3.745098 0.607167 Rocky III (1982) 2.361702 2.943503 0.581801 Caddyshack (1980) 3.396135 3.969737 0.573602 For a Few Dollars More (1965) 3.409091 3.953795 0.544704 Porky's (1981) 2.296875 2.836364 0.539489 Animal House (1978) 3.628906 4.167192 0.538286 Exorcist, The (1973) 3.537634 4.067239 0.529605 Fright Night (1985) 2.973684 3.500000 0.526316 Barb Wire (1996) 1.585366 2.100386 0.515020
如果只是想要找出分歧最大的电影(不考虑性别因素),则可以计算得分数据的方差或标准差:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
#根据电影名称分组的得分数据的标准差 rating_std_by_title = data.groupby('title')['rating'].std() #跟据active_titles进行过滤 rating_std_by_title = rating_std_by_title.iloc[active_titles] #根据值对Series进行降序排列 rating_std_by_title.sort_values(ascending=False)[:10] Out[114]: title Dumb & Dumber (1994) 1.321333 Blair Witch Project, The (1999) 1.316368 Natural Born Killers (1994) 1.307198 Tank Girl (1995) 1.277695 Rocky Horror Picture Show, The (1975) 1.260177 Eyes Wide Shut (1999) 1.259624 Evita (1996) 1.253631 Billy Madison (1995) 1.249970 Fear and Loathing in Las Vegas (1998) 1.246408 Bicentennial Man (1999) 1.245533 Name: rating, dtype: float64
os.chdir('/Users/yueqiang/Python Coding/python data analysis data/datasets/')
years = range(1880,2011) pieces = [] columns = ['name','sex','births']
for year in years: path = 'babynames/yob%d.txt' % year frame = pd.read_csv(path,names=columns) frame['year'] = year pieces.append(frame) names = pd.concat(pieces,ignore_index=True)
数据聚合
利用groupby或pivot_table在year和sex级别上对其进行聚合。
1 2 3 4 5 6 7 8 9 10 11 12
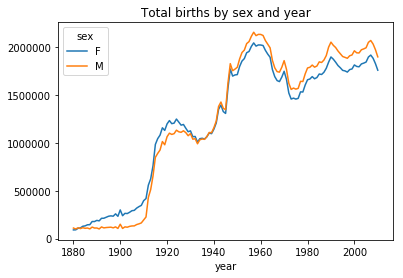
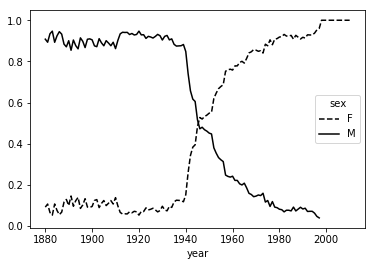
total_births = names.pivot_table('births',index='year',columns='sex',aggfunc=sum) total_births.tail() Out[122]: sex F M year 2006 1896468 2050234 2007 1916888 2069242 2008 1883645 2032310 2009 1827643 1973359 2010 1759010 1898382
total_births.plot(title='Total births by sex and year')
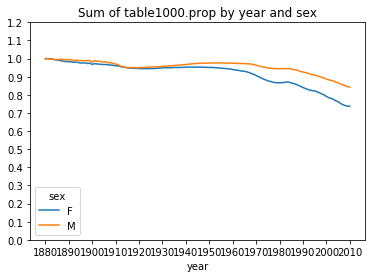
table = top1000.pivot_table('prop',index='year',columns='sex',aggfunc=sum) table.plot(title='Sum of table1000.prop by year and sex',yticks=np.linspace(0,1.2,13),xticks=range(1880,2020,10))
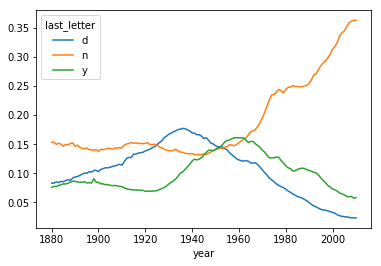
table = filterd.pivot_table('births',index='year',columns='sex',aggfunc='sum') table = table.div(table.sum(1),axis=0) table.tail() Out[213]: sex F M year 2006 1.0 NaN 2007 1.0 NaN 2008 1.0 NaN 2009 1.0 NaN 2010 1.0 NaN